
Semantic Role Labeling
Introduction
Natural language analysis techniques consist of lexical, syntactic, and semantic analysis. Semantic Role Labeling (SRL) is an instance of Shallow Semantic Analysis.
In a sentence :
- A predicate states a property or a characterization of a subject, such as what it does and what it is like.
- The predicate represents the core of an event, whereas the words accompanying the predicate are arguments.
- A semantic role refers to the abstract role an argument of a predicate take on in the event, including agent, patient, theme, experiencer, beneficiary, instrument, location, goal, and source.
Consider an example of semantic role labeling below :
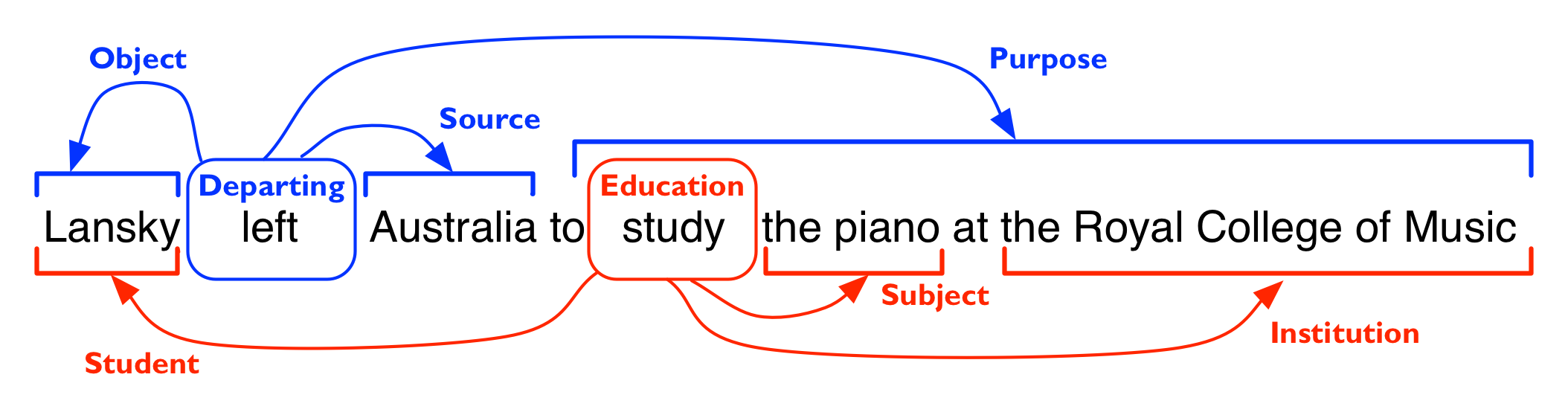
- Here the predicate (verb) is leave
- The object of leave is ‘Lansky ‘(A student)
- The source from where she left is ‘Australia’
- The purpose of leaving is to ‘study the Piano at Royal College of Music’
Applications of Semantic Role Labeling (SRL) :
SRL is useful as an intermediate step in a wide range of natural language processing (NLP) tasks, such as information extraction, automatic document categorization, question answering etc.
SRL System Implementation
SRL is considered as a supervised machine learning problem. In traditional methods , linear classifiers such as Logistic Regression, SVM were often employed to perform this task based on features extracted from the training corpus.
Syntactic information is considered to play an essential role in solving this problem. The location of an argument on syntactic tree provides an intermediate tag for improving the performance. However building this Syntactic tree also introduces prediction risk inevitably. The analysis in (Pradhan et al. 2005) fount that the major source of the incorrect predictions was the syntactic parser.
To overcome this problem, (Collobert et al., 2011) proposed a unified neural network architecture using word embeddings and convolution. However they had to resort to parsing features in order to make the system competitive.
SRL using Deep Learning
This post i wanted to introduce the new neural network which has given very good results on semantic role labeling
It is an end-to-end system using bi-directional long short-term memory (DB-LSTM) which was presented in :
End-to-end learning of semantic role labeling using recurrent neural networks (Zhou & Xu International joint conference on Natural Language Processing, 2015 )
Recurrent Neural Network (RNN) has advantage in modeling sequencing problems. The past information is built up through the recurrent layer when model consumes the sequence word by word.
People often met with two difficulties with RNN :
- Information of the current word strongly depends on distant words, rather than its neighborhood.
- Gradient parameters may explode or vanish especially in processing long sequences (Bengio et al. 1994) .
Long short-term memory (LSTM) (Hochreiter and Schmidhuber, 1997) was proposed to address the above difficulties.
In language related problems, the structural knowledge can be extracted by processing sequences both forward and backward so that the complementary information from the past and the future can be integrated for inference.
The Deep Bi-directional LSTM (DB-LSTM)
The Deep Bi-directional LSTM (DB-LSTM) topology used in the paper is explained as follows :
- A Standard LSTM processes the sequence in forward direction. The output of this LSTM layer is taken by the next LSTM layer as input, processed in reversed direction. These two standard LSTM composes a pair of LSTM.
- Then this LSTM layer pair is stacked pair after pair to obtain the deep LSTM Model.
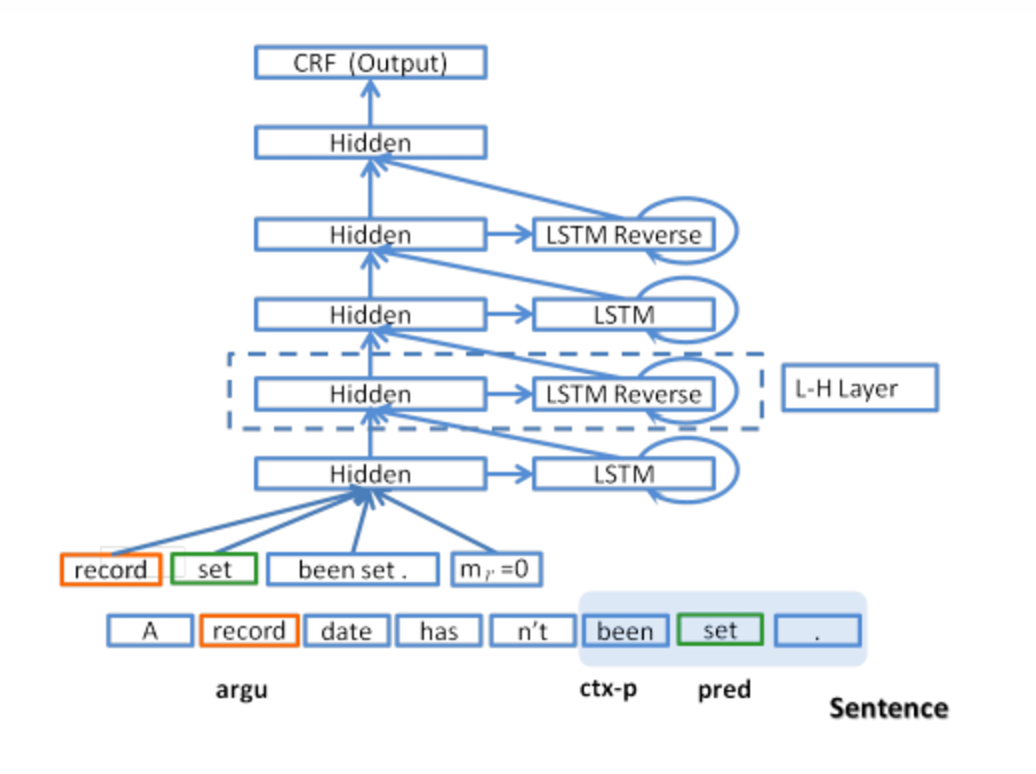
Features used by the model :
The model uses four features:
- predicate (or verb) – if a sentence has multiple predicates it will be processed multiple times, once for each
- argument – the word currently being processed as we move along the sentence
- predicate-context (ctx_p), the n words either side of the predicate
- region-mark – a boolean (0 or 1) value indicating whether the current argument falls within the predicate-context region.
The output is is the semantic role of each word. For the sentence “A record date hasn’t been set.”, this results in the following feature inputs and outputs:
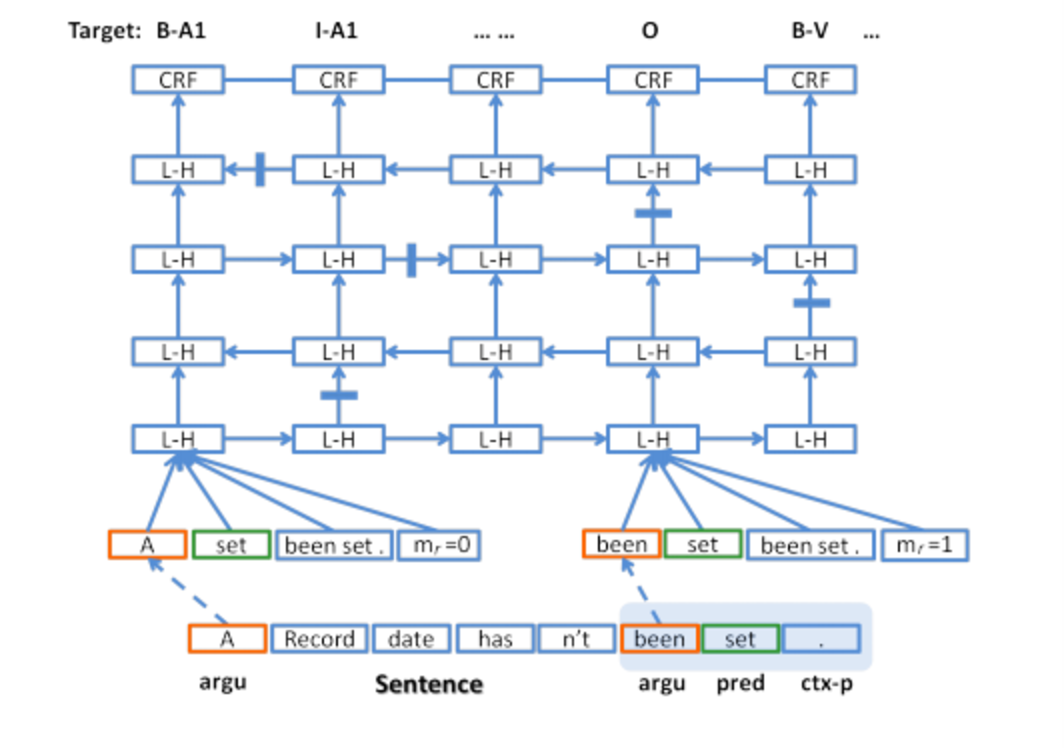
Here’s a temporal expanded version of the model (4 layers shown), with L-H representing a hidden LSTM layer.
Handling Data Sparsity
Pre-trained word embedings are used to address the data sparsity issue.
Training Algorithm
Stochastic gradient descent (SGD) algorithm is used as the training technique for the whole pipeline.
Overall the model was evaluated on the CoNLL-2005 shared task and achieved state of the art F1 score of 81.07
It is encouraging to see that deep learning models with end-to-end training can outperform traditional models on tasks which are previously believed to heavily depend on syntactic parsing.
There are still many improvements to be made before this models can become widely applicable in industries.
Leave a Comment