
Meanings are Vectors
Table of Content
Introduction
A recent big idea in natural language processing is that “meanings are vectors” . The approximate meaning of a word or phrase can be represented as a vector in a multi-dimensional space. Vectors that are close to each other represent similar meanings.
We will explore different versions of this vectors in this post.
Neural Word Embeddings
Word embeddings are one of the most exciting area of research in deep learning.
A neural word embedding \(W: \mathrm{words} \to \mathbb{R}^n\) is a paramaterized function mapping words in some language to high-dimensional vectors (perhaps 200 to 500 dimensions). For example, we might find:
\[\mathsf{W("pair")=(0.2, -0.4, 0.7, ...)}\] \[\mathsf{W("pear")=(0.0, -0.1, 0.1, ...)}\]In essence, it is a numerical vector to represent a word.
Their applications extends beyond sentences. It can be applied just as well to genes, code, likes, playlists, social media graphs and other verbal or symbolic series in which patterns may be discerned.
The purpose and usefulness of word embeddings is to group the vectors of similar words together in vectorspace. That is, it detects similarities mathematically.These vectors are distributed numerical representations of word features, features such as the context of individual words. And, all this is done without human intervention.
Word clusters can form the basis of search, sentiment analysis and recommendations in such diverse fields as scientific research, legal discovery, e-commerce and customer relationship management.
Now we will look at different variants of word embeddings.
Word2Vec
Word2vec was created by a team of researchers led by Tomas Mikolov at Google. It is described in this paper.
Word2vec is a two-layer neural net that processes text. The input to the network is a text corpus and its output is a set of vectors: feature vectors for words in that corpus. Word2vec is not a deep neural network per se, however it is very useful as it turns text into a numerical form that that deep networks can understand.
The motivation behind Word2vec is captured by Firth’s hypothesis from 1957:
“You shall know a word by the company it keeps.”
To give an example, if I ask you to think of a word that tends to co-occur with cow, drink, calcium, you would immediately answer: milk.
Words can be considered as discrete states and then we are simply looking for the transitional probabilities between those states: the likelihood that they will co-occur.
Mikolov et al. (2013b) presented the popular word2vec framework for learning word vectors.
In this framework, every word is mapped to a unique vector, represented by a column in a matrix W. The column is indexed by position of the word in the vocabulary. The concatenation or sum of the vectors is then used as features for prediction of the next word in a sentence.
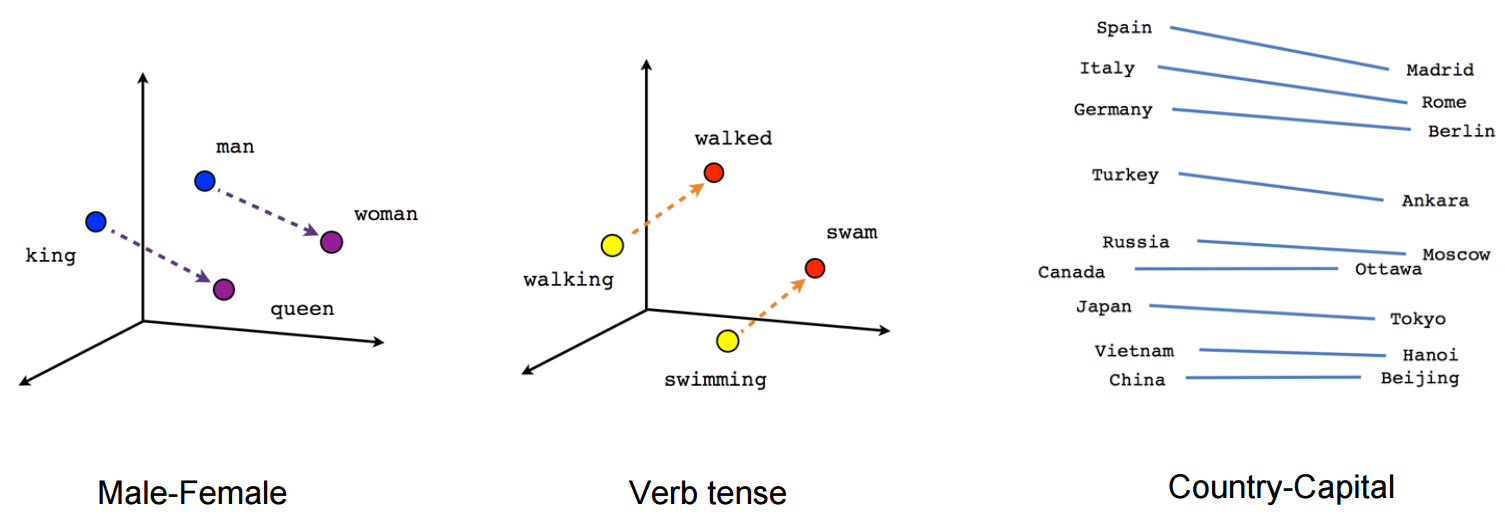
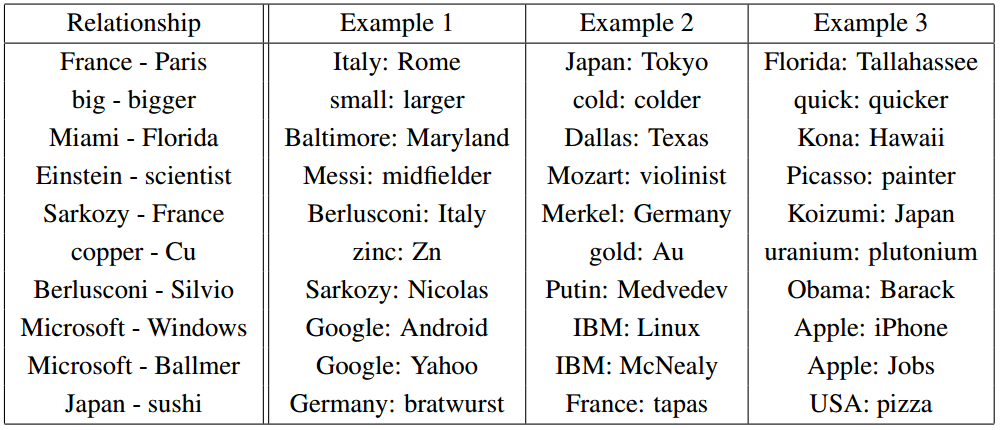
Given enough data, usage and contexts, Word2vec can make highly accurate guesses about a word’s meaning based on past appearances.
Those guesses can be used to establish a word’s association with other words in terms of vector arithmetics. For example:
\[W(``\text{woman}\!") - W(``\text{man}\!") ~\simeq~ W(``\text{queen}\!") - W(``\text{king}\!")\]The imabe below shows the relationship pairs described by Mikolov.
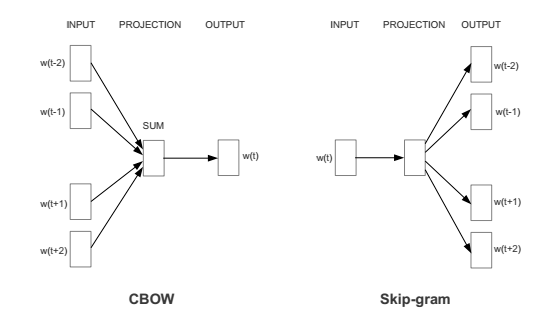
Word2Vec Architectures
Word2vec trains words against other words that neighbor them in the input corpus.
Word2vec comes in two flavors:
- Continuous bag of words (CBOW)
- Context (surrounding words) is used to predict the target word.
- Skip-gram with negative sampling or Skip-gram
- A word is used to predict a target context (surrounding words)
- This method can also work well with small amount of the training data. It can also represents rare words or phrases pretty well.
The image below shows the two architectures:
References:
- https://arxiv.org/pdf/1301.3781.pdf
- https://multithreaded.stitchfix.com/blog/2015/03/11/word-is-worth-a-thousand-vectors/
- https://www.slideshare.net/roelofp/041114-dl-nlpwordembeddings
- https://github.com/3Top/word2vec-api#where-to-get-a-pretrained-models
Glove
Stanford’s GloVe: Global Vectors for Word Representation is an unsupervised learning algorithm for obtaining vector representations for words.
Training is performed on aggregated global word-word co-occurrence statistics from a corpus, and the resulting representations showcase interesting linear substructures of the word vector space.
Levy et al. reported that there is no significant performance difference between different word embeddings implementations like Glove, Word2vec etc.
In my work on some classification tasks, i found Glove to perform better than Word2vec . I used publicly available models for word2vec and Glove
Dependency based word embeddings
Current models like word2vec, glove are based solely on linear contexts. In this work, Levy and Goldberg have generalized the skip-gram model with negative sampling introduced by Mikolov et al. to include arbitrary context. Specifically they have experimented with syntactic context.
The original implementation of Skip-Gram assumes bag-of-words contexts, that is, neighboring words.
Dependency-based embeddings are qualitatively different from the original embeddings.
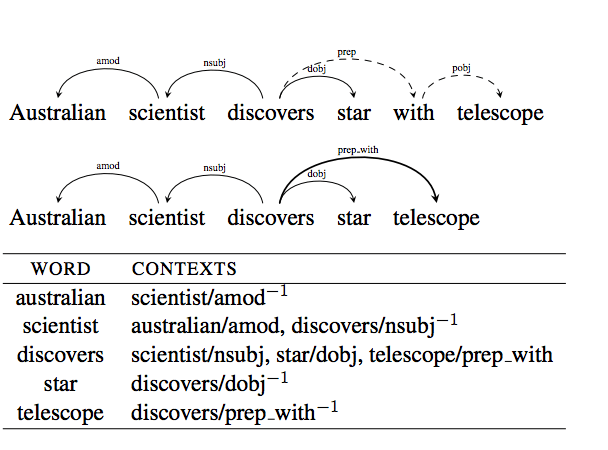
The dependency based embeddings are less topical and exhibit more functional similarity than the original skip-gram embeddings.

Code, Word Embeddings and Demo can be found at Omer Levy’s blog
Extensions of Word Embeddings beyond words
The word2vec model has been extened to work beyond different words. Two popular methods are described below:
- Paragraph Vector
- Skip-thought Vectors
Paragraph Vector
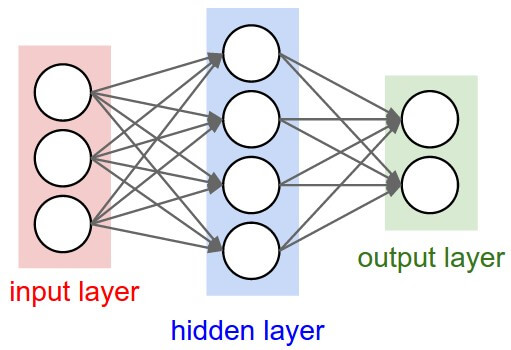
The paragraph vectors are inspired by the methods for learning the word vectors. They learn unsupervised representations of arbitrarily-long paragraphs/documents, based on an extension of the word2vec model.
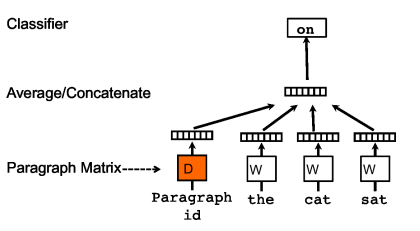
This framework is similar to the framework presented in Figure 1; the only change is the additional paragraph token that is mapped to a vector via matrix D. In this model, the concatenation or average of this vector with a context of three words is used to predict the fourth word. The paragraph vector represents the missing information from the current context and can act as a memory of the topic of the paragraph.
There are two version of paragraph vectors :
- Distributed Memory version of Paragraph Vector (PV-DM)
- Distributed Bag of Words version of Paragraph Vector (PV-DBOW)
Distributed Memory version of Paragraph Vector (PV-DM)
The framework we discussed above is PV-DM version. It considers the paragraph vector with the word vectors to predict the next word in a text window.
Distributed Bag of Words version of Paragraph Vector (PV-DBOW)
This method ignores the context words in the input. The paragraph vector is trained to predict the words in a small window. This method requires less storage and is very similar to the skip-gram modesl in word vectors (Mikolov et al., 2013c)
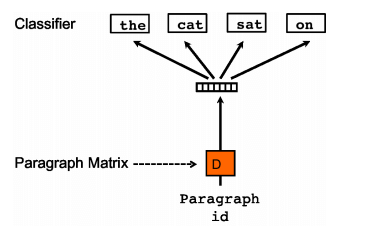
From expirements described in Mikolov’s paper on paragraph vectors combination of PV-DM with PV-DBOW is more consistent across many tasks like Sentiment Analysis , Information retrieval.
Skip-Thought Vectors
Skip-Thought Vectors are unsupervised sentence vectors. The inspiration is word vector learning. This method abstracts the skip-gram model of words to sentences the sentence level. So, instead of using a word to predit its surrounding context (or words in this case), Skip thoughts encode a sentence to predict the sentences around it.
Skip Thought Model requires having a training corpus of contiguous text. The paper trained on a large collection of novels, namely the BookCorpus dataset.

Given a tuple \({(s}_{i−1}, {s}_i, {s}_{i+1})\) of contiguous sentences, with \({s}_{i−1}\) the i-th sentence of a book, the sentence \({s}_{i}\) is encoded and tries to reconstruct the previous sentence \({s}_{i-1}\) and next sentence \({s}_{i+1}\) .
In this example, the input is the sentence triplet :
- I got back home.
- I could see the cat on the steps.
- This was strange.
Unattached arrows are connected to the encoder output. Colors indicate which components share parameters. \({<eos>}\) is the end of sentence token.
Skip-thoughts is the framework of encoder-decoder model. Encoderdecoder models have gained a lot of traction for neural machine translation.
- Encoder maps words to a sentence vector
- Decoder is used to generate the surrounding sentences. The decoder then conditions on this vector to generate a translation for the source English sentence.
Skip-thought model uses an RNN encoder with GRU activations and an RNN decoder with a conditional GRU.
The trained model in the paper was able to achieve state of the art performance on following tasks :
- Semantic relatedness (sentence similarity)
- Paraphrase detection
- Image-sentence ranking
- Question-type classification
- Sentiment and subjectivity datasets
Sent2Vec encoder and training code from the paper “Skip-Thought Vectors” is available on github.
I trained a skip-thought model for my work based on the public code. I found the current version of encoder to be really slow especially for large number of sentences.
Gensim Python Package
Gensim python package is robust, efficient for unsupervised semantic modelling from plain text. It has as very readable implementation of Word2Vec (and Doc2Vec).
Doc2vec (aka paragraph2vec, aka sentence embeddings) modifies the word2vec algorithm to unsupervised learning of continuous representations for larger blocks of text, such as sentences, paragraphs or entire documents. Gensim Doc2Vec
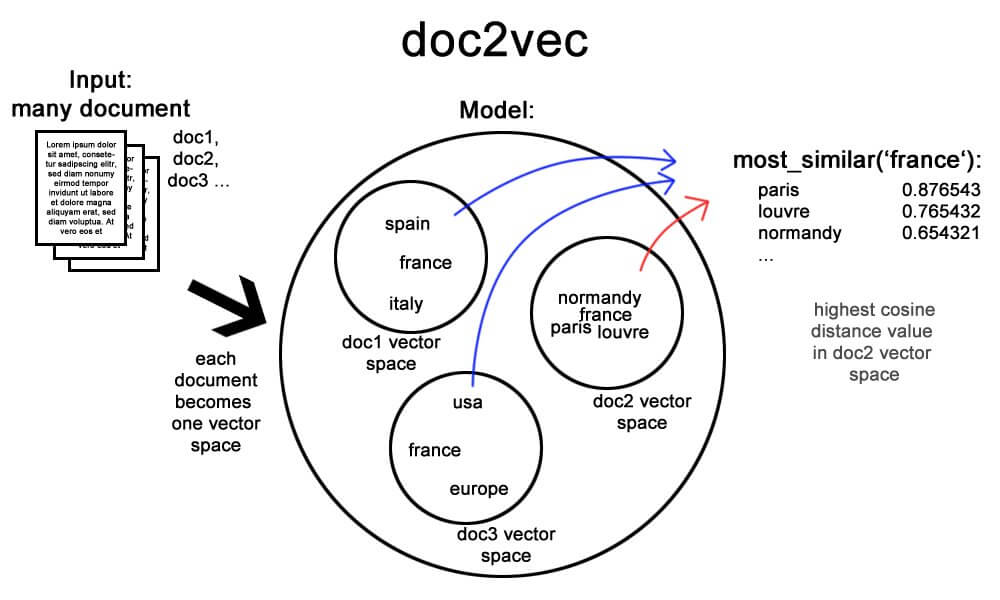
There are various tutorial online for how to use gensim for word2vec and doc2vec.
Leave a Comment