
Simplified Switchboard Corpus
We will create a simplified version of Switchboard Speech act corpus and perform exploratory data analysis on it.
Introduction
In this post we will do following tasks:
- We will create a simplified version of the switchboard speech-acts corpus
- We will perform exploratory data analysis on the switchboard corpus
About Switchboard corpus
The Switchboard Dialog Act Corpus (SwDA) extends the Switchboard-1 Telephone Speech Corpus, Release 2, with turn/utterance-level dialog-act tags. The tags summarize syntactic, semantic, and pragmatic information about the associated turn. The SwDA project was undertaken at UC Boulder in the late 1990s.
Recommended reading:
The manual for this Dataset can be found at :Switchboard DAMSL Dialogue Acts
Advantages of our version of dataset:
- It will be lot more clearer and easy to use.
- The creation of the corpus from the original files is automatic using Java code.
- It is also customizable so that we can extract different information from the corpus.
Steps for Creating our version of dataset:
1. Get the csv format of data from the link:
- (site) https://compprag.christopherpotts.net/swda.html
- (data) https://compprag.christopherpotts.net/code-data/swda.zip
2. Creating one csv file :
1. Concatenate all the csv files to one single file :
On Linux :
- Download the zip file and go inside switchboard-csv directory
- Issue following commands :
cat */*.csv > concetanated.csv
grep -v "swda_filename,ptb_basename,conversation_no,transcript_index,act_tag,caller,utterance_index,subutterance_index,text,pos,trees,ptb_treenumbers" yo.csv > filtered.csv
2. Add New Row Header
Add
"swda_filename,ptb_basename,conversation_no,transcript_index,act_tag,caller,utterance_index,subutterance_index,text,pos,trees,ptb_treenumbers" (without the quotes ) as the first row in filtered.csv file
3. Cleaning data and creating different format of csv files
1. Processing using Java Code
- I have created Java code to deal with cleaning data and creating different formats of data.
- Please have a look at the Java code for more information. This code can clean text, tags and produce different csv versions of the switchboard data.
- The final dataset can be downloaded from here
Exploratory Data Analysis of Switchboard Corpus
We will use ‘R’ to perform the exploratory analysis of data.
Load the Corpus
Let’s load the extended version of csv file creating from the Java code.
The dataset looks like following :
# Load the feature file
pandoc.table(head(data), style = "grid")
##
##
## +--------------------------+----------------+-------------------+
## | swda_filename | ptb_basename | conversation_no |
## +==========================+================+===================+
## | sw00utt/sw_0001_4325.utt | 4/sw4325 | 4325 |
## +--------------------------+----------------+-------------------+
## | sw00utt/sw_0001_4325.utt | 4/sw4325 | 4325 |
## +--------------------------+----------------+-------------------+
## | sw00utt/sw_0001_4325.utt | 4/sw4325 | 4325 |
## +--------------------------+----------------+-------------------+
## | sw00utt/sw_0001_4325.utt | 4/sw4325 | 4325 |
## +--------------------------+----------------+-------------------+
## | sw00utt/sw_0001_4325.utt | 4/sw4325 | 4325 |
## +--------------------------+----------------+-------------------+
## | sw00utt/sw_0001_4325.utt | 4/sw4325 | 4325 |
## +--------------------------+----------------+-------------------+
##
## Table: Table continues below
##
##
##
## +--------------------+-----------+------------------------------+
## | transcript_index | act_tag | act_label_1 |
## +====================+===========+==============================+
## | 0 | o | Other |
## +--------------------+-----------+------------------------------+
## | 1 | qw | Info-request:Wh-Question |
## +--------------------+-----------+------------------------------+
## | 2 | qy^d | Info-request:Yes-No-Question |
## +--------------------+-----------+------------------------------+
## | 3 | + | Other:Segment |
## | | | (multi-utterance) |
## +--------------------+-----------+------------------------------+
## | 4 | + | Other:Segment |
## | | | (multi-utterance) |
## +--------------------+-----------+------------------------------+
## | 5 | qy | Info-request:Yes-No-Question |
## +--------------------+-----------+------------------------------+
##
## Table: Table continues below
##
##
##
## +--------------+---------------------------+------------+---------------+
## | label1_0 | label1_1 | label1_2 | act_label_2 |
## +==============+===========================+============+===============+
## | Other | | | none |
## +--------------+---------------------------+------------+---------------+
## | Info-request | Wh-Question | | none |
## +--------------+---------------------------+------------+---------------+
## | Info-request | Yes-No-Question | | none |
## +--------------+---------------------------+------------+---------------+
## | Other | Segment (multi-utterance) | | none |
## +--------------+---------------------------+------------+---------------+
## | Other | Segment (multi-utterance) | | none |
## +--------------+---------------------------+------------+---------------+
## | Info-request | Yes-No-Question | | none |
## +--------------+---------------------------+------------+---------------+
##
## Table: Table continues below
##
##
##
## +------------+------------+------------+----------------------+----------+
## | label2_0 | label2_1 | label2_2 | act_label_relation | caller |
## +============+============+============+======================+==========+
## | none | | | none | A |
## +------------+------------+------------+----------------------+----------+
## | none | | | none | A |
## +------------+------------+------------+----------------------+----------+
## | none | | | none | B |
## +------------+------------+------------+----------------------+----------+
## | none | | | none | A |
## +------------+------------+------------+----------------------+----------+
## | none | | | none | B |
## +------------+------------+------------+----------------------+----------+
## | none | | | none | A |
## +------------+------------+------------+----------------------+----------+
##
## Table: Table continues below
##
##
##
## +-------------------+----------------------+--------------------------------+
## | utterance_index | subutterance_index | text |
## +===================+======================+================================+
## | 1 | 1 | Okay. / |
## +-------------------+----------------------+--------------------------------+
## | 1 | 2 | {D So, } |
## +-------------------+----------------------+--------------------------------+
## | 2 | 1 | [ [ I guess, + |
## +-------------------+----------------------+--------------------------------+
## | 3 | 1 | What kind of experience [ do |
## | | | you, + do you ] have, then |
## | | | with child care? / |
## +-------------------+----------------------+--------------------------------+
## | 4 | 1 | I think, ] + {F uh, } I wonder |
## | | | ] if that worked. / |
## +-------------------+----------------------+--------------------------------+
## | 5 | 1 | Does it say something? / |
## +-------------------+----------------------+--------------------------------+
##
## Table: Table continues below
##
##
##
## +-------------------------------+
## | clean_text |
## +===============================+
## | Okay. |
## +-------------------------------+
## | So, |
## +-------------------------------+
## | I guess, |
## +-------------------------------+
## | What kind of experience do |
## | you, do you have, then with |
## | child care ? |
## +-------------------------------+
## | I think, uh, I wonder if that |
## | worked. |
## +-------------------------------+
## | Does it say something ? |
## +-------------------------------+
Exploration of SwitchBoard Data
Let’s look at various information
Topics
Total number of topics in the corpus:
nrow(d)
## [1] 66
Plot of Topics and their total number of files
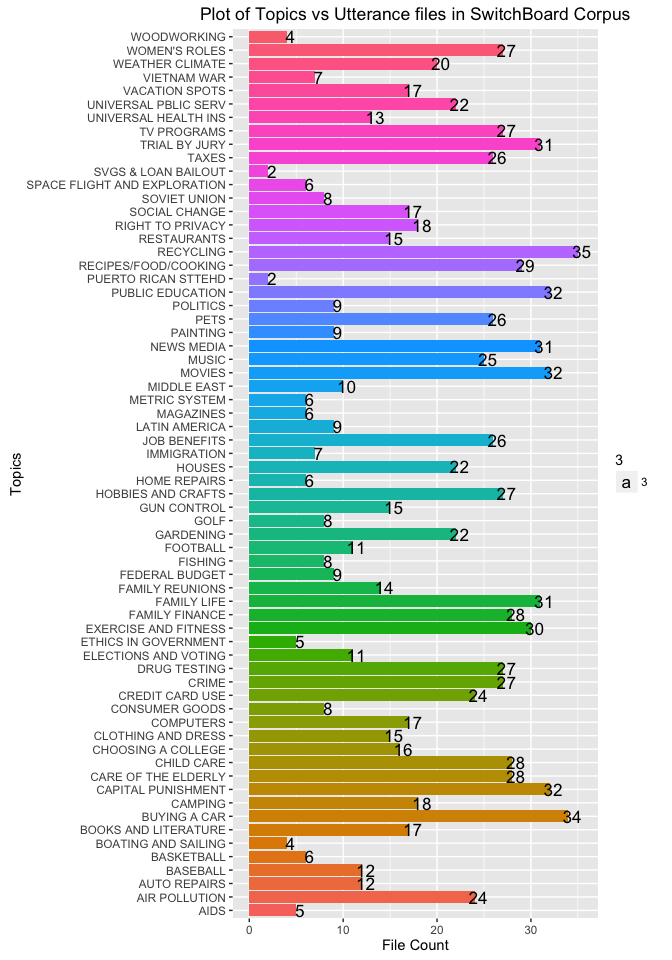
Number of unique files in the corpus
nrow(file_counts)
## [1] 1155
Conversations in the corpus
Plot of Average conversation length per topic
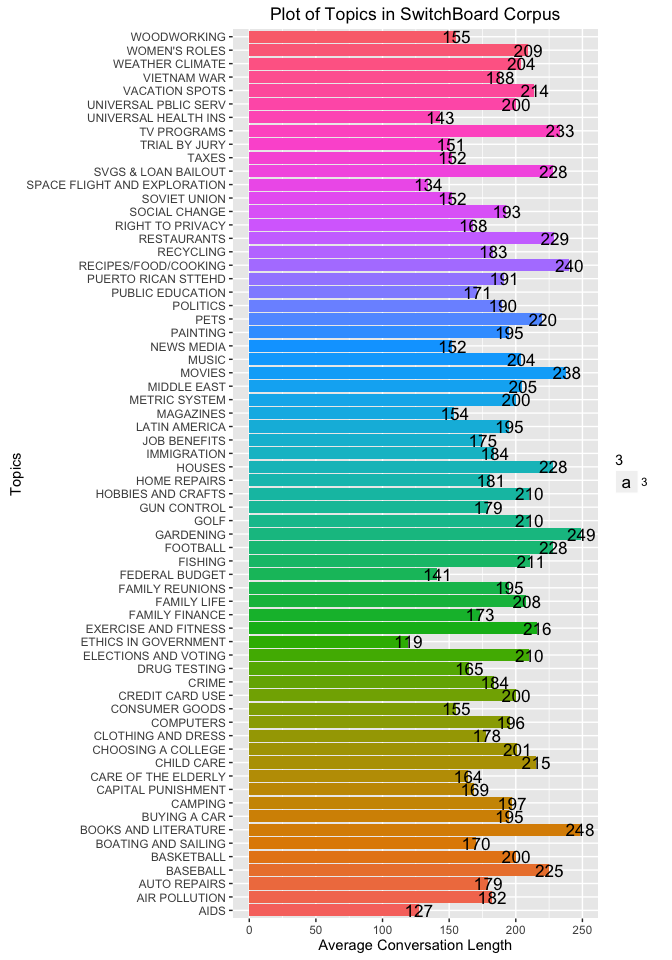
Histogram of Average conversation length per utterance file
Average conversation length per utterance file
avg
## [1] 193.5983
Speech Acts in the Corpus
Speech Acts in SwitchBoard Corpus are arranged in Hierarchy. Please refer to manaul to know more about them.
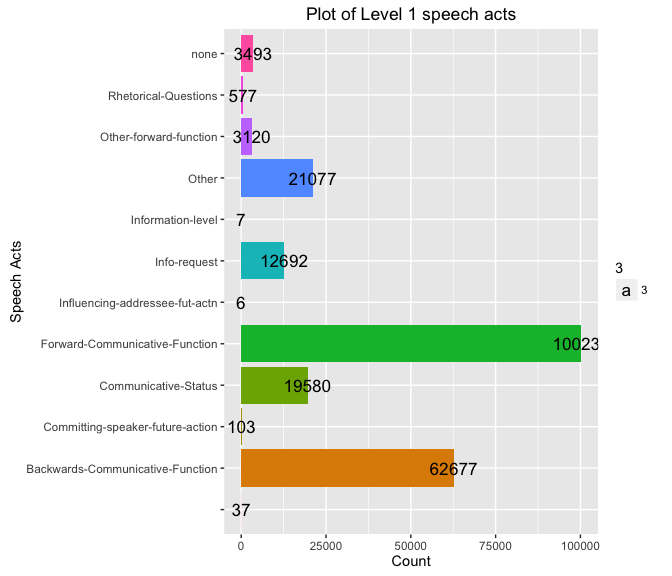
Level 1 Hierarchy
Total number of Level 1 speech acts in the corpus:
nrow(d)
## [1] 12
Plot of Level 1 Speech acts and their count
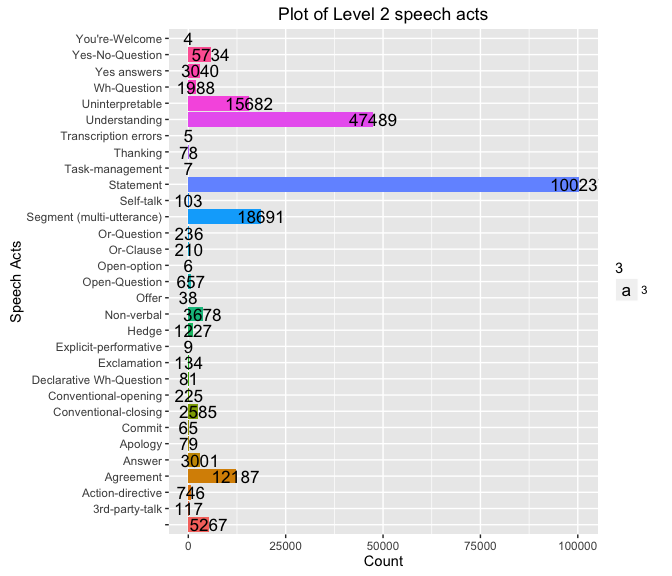
Level 2 Hierarchy
Total number of Level 2 speech acts in the corpus:
nrow(d)
## [1] 31
Plot of Level 2 speech acts and their count
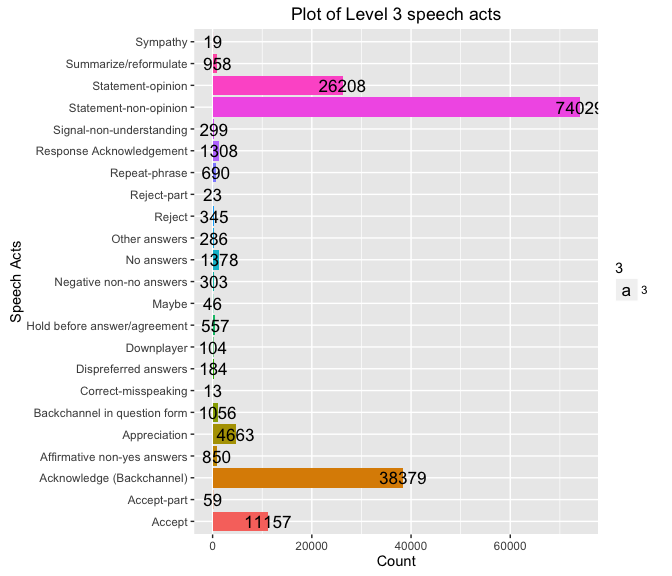
 ### Level 3 Hierarchy
### Level 3 Hierarchy
Total number of Level 3 speech acts in the corpus:
nrow(d)
## [1] 23
Plot of Level 3 speech acts and their count
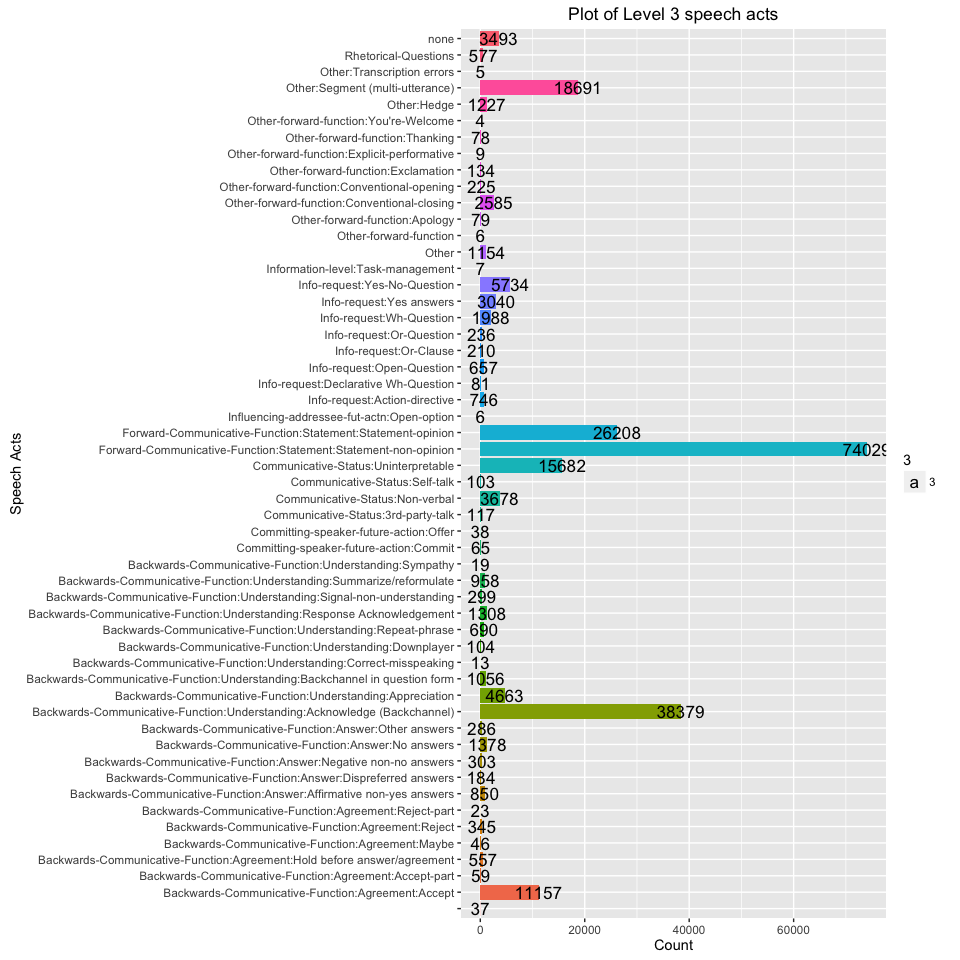
All labels
Total number of all speech acts in the corpus:
nrow(d)
## [1] 54
Plot of all speech acts and their count
Leave a Comment